Use Azure OpenAI Models
Use OpenAI models deployed through Azure services in your pipelines.
For a list of supported models, see Azure documentation.
Prerequisites
You need an Azure OpenAI API key and Azure OpenAI endpoint. For details, see Azure REST API reference.
Use Azure OpenAI
First, connect deepset AI Platform to Azure through the Integrations page. You can set up the connection for a single workspace or for the whole organization:
Add Workspace-Level Integration
- Click your profile icon and choose Settings.
- Go to Workspace>Integrations.
- Find the provider you want to connect and click Connect next to them.
- Enter the API key and any other required details.
- Click Connect. You can use this integration in pipelines and indexes in the current workspace.
Add Organization-Level Integration
- Click your profile icon and choose Settings.
- Go to Organization>Integrations.
- Find the provider you want to connect and click Connect next to them.
- Enter the API key and any other required details.
- Click Connect. You can use this integration in pipelines and indexes in all workspaces in the current organization.
Then, add a component that uses an OpenAI model through Azure to your pipeline. Here are the components by the model type they use:
-
Embedding models:
AzureOpenAITextEmbedder: Calculates embeddings for text, like query. Often used in query pipelines to embed a query and pass the embedding to an embedding retriever.AzureOpenAIDocumentEmbedder: Calculates embeddings for documents. Often used in indexes to embed documents and pass them to DocumentWriter.Embedding Models in Query Pipelines and Indexes
The embedding model you use to embed documents in your indexing pipeline must be the same as the embedding model you use to embed the query in your query pipeline.
This means the embedders for your indexing and query pipelines must match. For example, if you use
CohereDocumentEmbedderto embed your documents, you should useCohereTextEmbedderwith the same model to embed your queries.
-
LLMs:
AzureOpenAIGenerator: Generates text using OpenAI models hosted on Azure, often used in RAG pipelines.
Usage Examples
This is an example of how to use embedding models and an LLM hosted on Azure in an index and a query pipeline (each in a separate tab):
- Index
- Query Pipeline
components:
...
splitter:
type: haystack.components.preprocessors.document_splitter.DocumentSplitter
init_parameters:
split_by: word
split_length: 250
split_overlap: 30
document_embedder:
type: haystack.components.embedders.azure_document_embedder.AzureOpenAIDocumentEmbedder
init_parameters:
azure_deployment: "text-embedding-ada-002" # this is the name of the model you want to use
writer:
type: haystack.components.writers.document_writer.DocumentWriter
init_parameters:
document_store:
type: haystack_integrations.document_stores.opensearch.document_store.OpenSearchDocumentStore
init_parameters:
embedding_dim: 768
similarity: cosine
policy: OVERWRITE
connections: # Defines how the components are connected
...
- sender: splitter.documents
receiver: document_embedder.documents
- sender: document_embedder.documents
receiver: writer.documents
components:
...
query_embedder:
type: haystack.components.embedders.azure_text_embedder.AzureOpenAITextEmbedder
init_parameters:
azure_endpoint: "https://your-company.azure.openai.com/"
azure_deployment: "text-embedding-ada-002" #this is the name of the model you want to use
retriever:
type: haystack_integrations.components.retrievers.opensearch.embedding_retriever.OpenSearchEmbeddingRetriever
init_parameters:
document_store:
init_parameters:
use_ssl: True
verify_certs: False
http_auth:
- "${OPENSEARCH_USER}"
- "${OPENSEARCH_PASSWORD}"
type: haystack_integrations.document_stores.opensearch.document_store.OpenSearchDocumentStore
top_k: 20
prompt_builder:
type: haystack.components.builders.prompt_builder.PromptBuilder
init_parameters:
template: |-
You are a technical expert.
You answer questions truthfully based on provided documents.
For each document check whether it is related to the question.
Only use documents that are related to the question to answer it.
Ignore documents that are not related to the question.
If the answer exists in several documents, summarize them.
Only answer based on the documents provided. Don't make things up.
If the documents can't answer the question or you are unsure say: 'The answer can't be found in the text'.
These are the documents:
{% for document in documents %}
Document[{{ loop.index }}]:
{{ document.content }}
{% endfor %}
Question: {{question}}
Answer:
generator:
type: haystack.components.generators.azure.AzureOpenAIGenerator
init_parameters:
generation_kwargs:
temperature: 0.0
azure_deployment: gpt-35-turbo #this is the model you want to use
answer_builder:
init_parameters: {}
type: haystack.components.builders.answer_builder.AnswerBuilder
...
connections: # Defines how the components are connected
...
- sender: query_embedder.embedding # AmazonBedrockTextEmbedder sends the embedded query to the retriever
receiver: retriever.query_embedding
- sender: retriever.documents
receiver: prompt_builder.documents
- sender: prompt_builder.prompt
receiver: generator.prompt
- sender: generator.replies
receiver: answer_builder.replies
...
inputs:
query:
..
- "query_embedder.text" # TextEmbedder needs query as input and it's not getting it
- "retriever.query" # from any component it's connected to, so it needs to receive it from the pipeline.
- "prompt_builder.question"
- "answer_builder.query"
...
...
The components in Pipeline Builder:
-
AzureOpenAIDocumentEmbedder(used in indexing pipelines):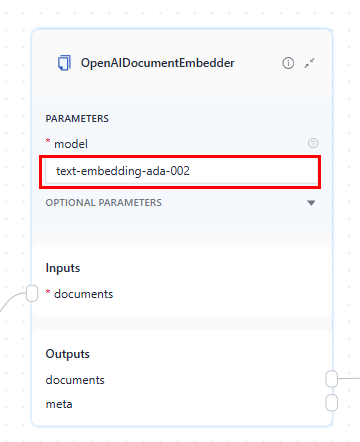
-
AzureOpenAITextEmbedder(used in query pipelines):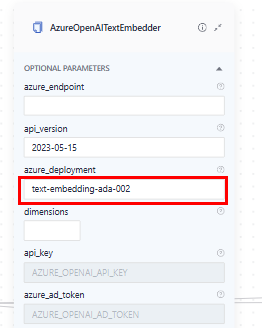
-
AzureOpenAIGenerator: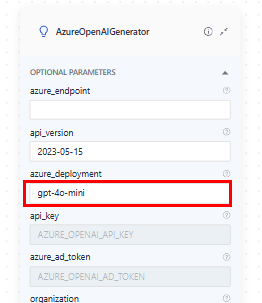
Was this page helpful?